



In an era of automation, dealing with textual data is one of the most tedious tasks to perform. Several machine learning techniques are introduced to reduce manual data entry and data mining as a solution to this.
Text Analysis
Text analysis classifies and automates extracted data that allows subject matter experts to dig in quickly. Textual data comes in various formats as comments on Facebook or Twitter, PDF format as a newspaper or annual reports, etc.
Describing technique available in Microsoft Azure ML Studio which helps to mine textual data are as follows:
- Detect Languages
- Extract Keyphrases from text
- Extract N-Gram features from text
- Feature Hashing
- Latent Dirichlet Allocation
- Named Entity Recognition
- Preprocess Text

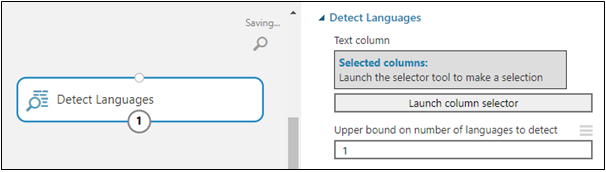
Detect Languages
The language detection algorithm can identify many different languages. Just specify the string column to analyze, along with the total number of languages to detect.
The algorithm will analyze each row of text and assign a probability score for each language. The language in the first result column is the language that got the highest score.
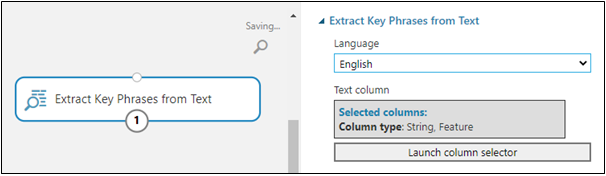
Extract Keyphrases from Text
A wrapper of Natural Language Processing API helps extract key phrases from a given column’s textual dataset. This module performs topic modeling on all rows of a provided column to get potential and sensible sentences.
This module captures the sentence’s topic and phases, combining the modifier and noun that indicates sentiments.
Extract Keyphrases from Text modules also contain language parameter which covers English, Spanish, French, Dutch, German, and Italian.
Extract N-Gram Features from Text
Extracting the N-Gram feature from the Text module helps us extract a meaningful phase from a given column of dataset sentences.
The module applies various information metrics to the n-gram list to reduce data dimensionality and identify the n-grams with the most information value.

Feature Hashing
Feature Hashing represents integers followed by transforming a given string of English text into a set of features.
It works by converting unique tokens into integers. It doesn’t provide any linguistic analysis or pre-processing on given input sentences.

Latent Dirichlet Allocation
Latent Dirichlet Allocation module performs Topic Modeling by using Natural Language Processing techniques. It groups unclassified text into several categories. This module takes a column of text and generates these outputs:
- The source text, together with a score for each category
- A feature matrix containing extracted terms and coefficients for each category
- A transformation, which you can save and reapply to the new text used as input

Named Entity Recognition
The Named Entity Recognition module identifies Person, Organisation, and Location in a given dataset. It also helps extract different types of data from other kinds of documents like Forms, News articles, etc., by developing custom modules. The Module is generally used to extract information from Twitter or Facebook comments, or other social media platforms.
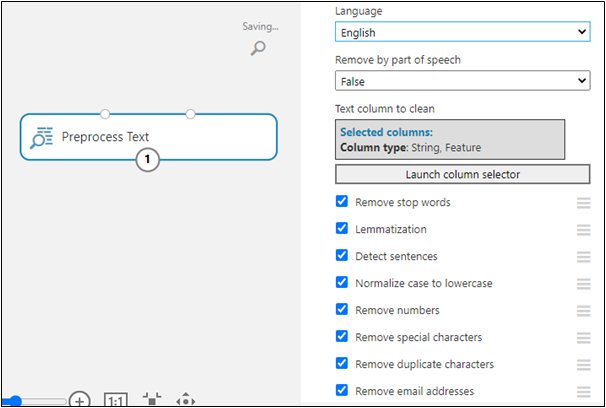
Preprocess Text
Preprocess Text module is to filter given dataset column with various parameters such as:
- Removal of stop-words
- Using regular expressions to search for and replace specific target strings
- Lemmatization, which converts multiple related words to a single canonical form
- Filtering on particular parts of speech
- Case normalization
- Removal of certain classes of characters, such as numbers, special symbols, and sequences of repeated characters such as “AAAA.”
- Identification and removal of emails and URLs
It Also Supports six different languages like English, Spanish, French, Italian, Dutch, and German.
We hope you know everything about text analysis using machine language now! In case of any queries do not forget to get in touch with an expert at DEV IT.